Python3 輸入和輸出
在前面幾個章節中,我們其實已經接觸了 Python 的輸入輸出的功能。本章節我們將具體介紹 Python 的輸入輸出。
輸出格式美化
Python兩種輸出值的方式: 運算式語句和 print() 函數。
第三種方式是使用檔對象的 write() 方法,標準輸出檔可以用 sys.stdout 引用。
如果你希望輸出的形式更加多樣,可以使用 str.format() 函數來格式化輸出值。
如果你希望將輸出的值轉成字串,可以使用 repr() 或 str() 函數來實現。
- str(): 函數返回一個用戶易讀的表達形式。
- repr(): 產生一個解釋器易讀的表達形式。
例如
>>> str(s)
'Hello, zaixian'
>>> repr(s)
"'Hello, zaixian'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'x 的值為: ' + repr(x) + ', y 的值為:' + repr(y) + '...'
>>> print(s)
x 的值為: 32.5, y 的值為:40000...
>>> # repr() 函數可以轉義字串中的特殊字元
... hello = 'hello, zaixian\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, zaixian\n'
>>> # repr() 的參數可以是 Python 的任何對象
... repr((x, y, ('Google', 'zaixian')))
"(32.5, 40000, ('Google', 'zaixian'))"
這裏有兩種方式輸出一個平方與立方的表:
... print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
... # 注意前一行 'end' 的使用
... print(repr(x*x*x).rjust(4))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
>>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
注意:在第一個例子中, 每列間的空格由 print() 添加。
這個例子展示了字串對象的 rjust() 方法, 它可以將字串靠右, 並在左邊填充空格。
還有類似的方法, 如 ljust() 和 center()。 這些方法並不會寫任何東西, 它們僅僅返回新的字串。
另一個方法 zfill(), 它會在數字的左邊填充 0,如下所示:
'00012'
>>> '-3.14'.zfill(7)
'-003.14'
>>> '3.14159265359'.zfill(5)
'3.14159265359'
str.format() 的基本使用如下:
IT研修網址: "www.xuhuhu.com!"
括弧及其裏面的字元 (稱作格式化字段) 將會被 format() 中的參數替換。
在括弧中的數字用於指向傳入對象在 format() 中的位置,如下所示:
Google 和 zaixian
>>> print('{1} 和 {0}'.format('Google', 'zaixian'))
zaixian 和 Google
如果在 format() 中使用了關鍵字參數, 那麼它們的值會指向使用該名字的參數。
IT研修網址: www.zaixian.com
位置及關鍵字參數可以任意的結合:
站點列表 Google, zaixian, 和 Taobao。
!a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用於在格式化某個值之前對其進行轉化:
>>> print('常量 PI 的值近似為: {}。'.format(math.pi))
常量 PI 的值近似為: 3.141592653589793。
>>> print('常量 PI 的值近似為: {!r}。'.format(math.pi))
常量 PI 的值近似為: 3.141592653589793。
可選項 : 和格式識別字可以跟著字段名。 這就允許對值進行更好的格式化。 下麵的例子將 Pi 保留到小數點後三位:
>>> print('常量 PI 的值近似為 {0:.3f}。'.format(math.pi))
常量 PI 的值近似為 3.142。
在 : 後傳入一個整數, 可以保證該域至少有這麼多的寬度。 用於美化表格時很有用。
>>> for name, number in table.items():
... print('{0:10} ==> {1:10d}'.format(name, number))
...
Google ==> 1
zaixian ==> 2
Taobao ==> 3
如果你有一個很長的格式化字串, 而你不想將它們分開, 那麼在格式化時通過變數名而非位置會是很好的事情。
最簡單的就是傳入一個字典, 然後使用方括號 [] 來訪問鍵值 :
>>> print('zaixian: {0[zaixian]:d}; Google: {0[Google]:d}; Taobao: {0[Taobao]:d}'.format(table))
zaixian: 2; Google: 1; Taobao: 3
也可以通過在 table 變數前使用 ** 來實現相同的功能:
>>> print('zaixian: {zaixian:d}; Google: {Google:d}; Taobao: {Taobao:d}'.format(**table))
zaixian: 2; Google: 1; Taobao: 3
舊式字串格式化
% 操作符也可以實現字串格式化。 它將左邊的參數作為類似 sprintf() 式的格式化字串, 而將右邊的代入, 然後返回格式化後的字串. 例如:
>>> print('常量 PI 的值近似為:%5.3f。' % math.pi)
常量 PI 的值近似為:3.142。
因為 str.format() 是比較新的函數, 大多數的 Python 代碼仍然使用 % 操作符。但是因為這種舊式的格式化最終會從該語言中移除, 應該更多的使用 str.format().
讀取鍵盤輸入
Python提供了 input() 內置函數從標準輸入讀入一行文本,默認的標準輸入是鍵盤。
input 可以接收一個Python運算式作為輸入,並將運算結果返回。
實例
str = input("請輸入:");
print ("你輸入的內容是: ", str)
這會產生如下的對應著輸入的結果:
請輸入:IT研修 你輸入的內容是: IT研修
讀和寫檔
open() 將會返回一個 file 對象,基本語法格式如下:
open(filename, mode)
- filename:包含了你要訪問的檔案名稱的字串值。
- mode:決定了打開檔的模式:只讀,寫入,追加等。所有可取值見如下的完全列表。這個參數是非強制的,默認檔訪問模式為只讀(r)。
不同模式打開檔的完全列表:
| 模式 | 描述 |
|---|---|
| r | 以只讀方式打開檔。檔的指針將會放在檔的開頭。這是默認模式。 |
| rb | 以二進位格式打開一個檔用於只讀。檔指針將會放在檔的開頭。 |
| r+ | 打開一個檔用於讀寫。檔指針將會放在檔的開頭。 |
| rb+ | 以二進位格式打開一個檔用於讀寫。檔指針將會放在檔的開頭。 |
| w | 打開一個檔只用於寫入。如果該檔已存在則打開檔,並從開頭開始編輯,即原有內容會被刪除。如果該檔不存在,創建新檔。 |
| wb | 以二進位格式打開一個檔只用於寫入。如果該檔已存在則打開檔,並從開頭開始編輯,即原有內容會被刪除。如果該檔不存在,創建新檔。 |
| w+ | 打開一個檔用於讀寫。如果該檔已存在則打開檔,並從開頭開始編輯,即原有內容會被刪除。如果該檔不存在,創建新檔。 |
| wb+ | 以二進位格式打開一個檔用於讀寫。如果該檔已存在則打開檔,並從開頭開始編輯,即原有內容會被刪除。如果該檔不存在,創建新檔。 |
| a | 打開一個檔用於追加。如果該檔已存在,檔指針將會放在檔的結尾。也就是說,新的內容將會被寫入到已有內容之後。如果該檔不存在,創建新檔進行寫入。 |
| ab | 以二進位格式打開一個檔用於追加。如果該檔已存在,檔指針將會放在檔的結尾。也就是說,新的內容將會被寫入到已有內容之後。如果該檔不存在,創建新檔進行寫入。 |
| a+ | 打開一個檔用於讀寫。如果該檔已存在,檔指針將會放在檔的結尾。檔打開時會是追加模式。如果該檔不存在,創建新檔用於讀寫。 |
| ab+ | 以二進位格式打開一個檔用於追加。如果該檔已存在,檔指針將會放在檔的結尾。如果該檔不存在,創建新檔用於讀寫。 |
下圖很好的總結了這幾種模式:
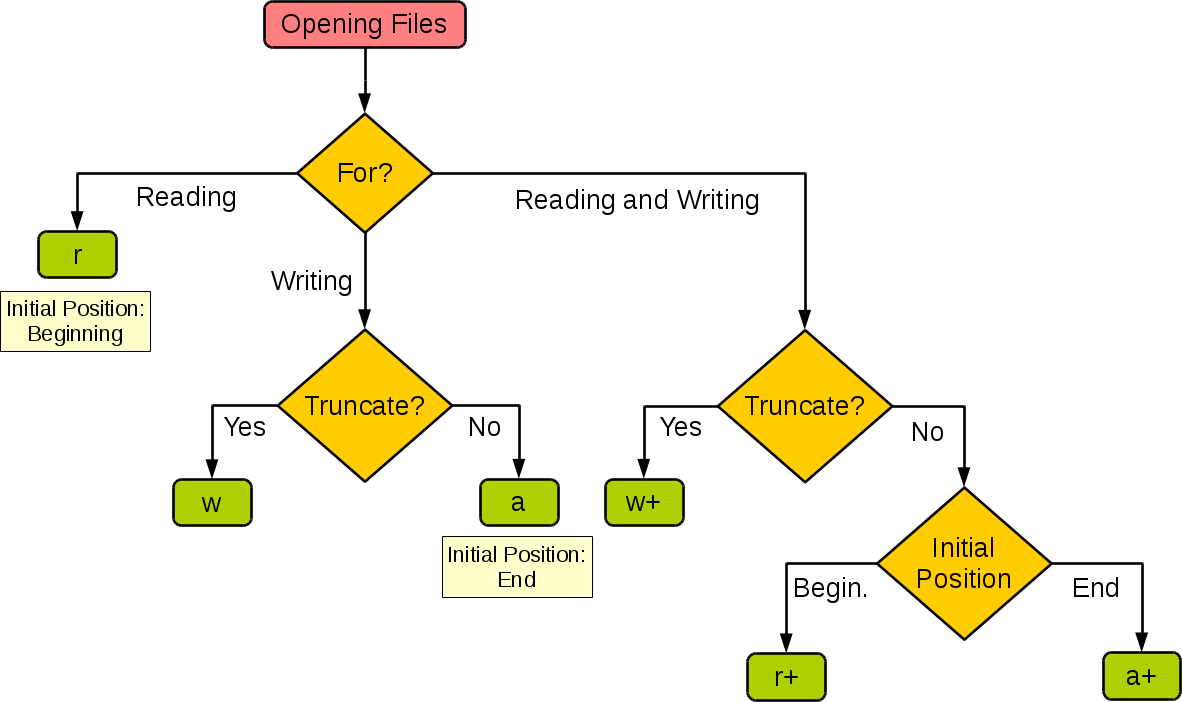
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 讀 | + | + | + | + | ||
| 寫 | + | + | + | + | + | |
| 創建 | + | + | + | + | ||
| 覆蓋 | + | + | ||||
| 指針在開始 | + | + | + | + | ||
| 指針在結尾 | + | + |
以下實例將字串寫入到檔 foo.txt 中:
實例
# 打開一個檔
f = open("/tmp/foo.txt", "w")
f.write( "Python 是一個非常好的語言。\n是的,的確非常好!!\n" )
# 關閉打開的檔
f.close()
- 第一個參數為要打開的檔案名。
- 第二個參數描述檔如何使用的字元。 mode 可以是 'r' 如果檔只讀, 'w' 只用於寫 (如果存在同名檔則將被刪除), 和 'a' 用於追加檔內容; 所寫的任何數據都會被自動增加到末尾. 'r+' 同時用於讀寫。 mode 參數是可選的; 'r' 將是默認值。
此時打開檔 foo.txt,顯示如下:
$ cat /tmp/foo.txt Python 是一個非常好的語言。 是的,的確非常好!!
檔對象的方法
本節中剩下的例子假設已經創建了一個稱為 f 的檔對象。
f.read()
為了讀取一個檔的內容,調用 f.read(size), 這將讀取一定數目的數據, 然後作為字串或位元組對象返回。
size 是一個可選的數字類型的參數。 當 size 被忽略了或者為負, 那麼該檔的所有內容都將被讀取並且返回。
以下實例假定檔 foo.txt 已存在(上面實例中已創建):
實例
# 打開一個檔
f = open("/tmp/foo.txt", "r")
str = f.read()
print(str)
# 關閉打開的檔
f.close()
執行以上程式,輸出結果為:
Python 是一個非常好的語言。 是的,的確非常好!!
f.readline()
f.readline() 會從檔中讀取單獨的一行。換行符為 '\n'。f.readline() 如果返回一個空字元串, 說明已經已經讀取到最後一行。
實例
# 打開一個檔
f = open("/tmp/foo.txt", "r")
str = f.readline()
print(str)
# 關閉打開的檔
f.close()
執行以上程式,輸出結果為:
Python 是一個非常好的語言。
f.readlines()
f.readlines() 將返回該檔中包含的所有行。
如果設置可選參數 sizehint, 則讀取指定長度的位元組, 並且將這些位元組按行分割。
實例
# 打開一個檔
f = open("/tmp/foo.txt", "r")
str = f.readlines()
print(str)
# 關閉打開的檔
f.close()
執行以上程式,輸出結果為:
['Python 是一個非常好的語言。\n', '是的,的確非常好!!\n']
另一種方式是迭代一個檔對象然後讀取每行:
實例
# 打開一個檔
f = open("/tmp/foo.txt", "r")
for line in f:
print(line, end='')
# 關閉打開的檔
f.close()
執行以上程式,輸出結果為:
Python 是一個非常好的語言。 是的,的確非常好!!
這個方法很簡單, 但是並沒有提供一個很好的控制。 因為兩者的處理機制不同, 最好不要混用。
f.write()
f.write(string) 將 string 寫入到檔中, 然後返回寫入的字元數。
實例
# 打開一個檔
f = open("/tmp/foo.txt", "w")
num = f.write( "Python 是一個非常好的語言。\n是的,的確非常好!!\n" )
print(num)
# 關閉打開的檔
f.close()
執行以上程式,輸出結果為:
29
如果要寫入一些不是字串的東西, 那麼將需要先進行轉換:
實例
# 打開一個檔
f = open("/tmp/foo1.txt", "w")
value = ('www.xuhuhu.com', 14)
s = str(value)
f.write(s)
# 關閉打開的檔
f.close()
執行以上程式,打開 foo1.txt 檔:
$ cat /tmp/foo1.txt
('www.xuhuhu.com', 14)
f.tell()
f.tell() 返回檔對象當前所處的位置, 它是從檔開頭開始算起的位元組數。
f.seek()
如果要改變檔當前的位置, 可以使用 f.seek(offset, from_what) 函數。
from_what 的值, 如果是 0 表示開頭, 如果是 1 表示當前位置, 2 表示檔的結尾,例如:
- seek(x,0) : 從起始位置即檔首行首字元開始移動 x 個字元
- seek(x,1) : 表示從當前位置往後移動x個字元
- seek(-x,2):表示從檔的結尾往前移動x個字元
from_what 值為默認為0,即檔開頭。下麵給出一個完整的例子:
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # 移動到檔的第六個位元組
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # 移動到檔的倒數第三位元組
13
>>> f.read(1)
b'd'
f.close()
在文本檔中 (那些打開檔的模式下沒有 b 的), 只會相對於檔起始位置進行定位。
當你處理完一個檔後, 調用 f.close() 來關閉檔並釋放系統的資源,如果嘗試再調用該檔,則會拋出異常。
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: I/O operation on closed file
當處理一個檔對象時, 使用 with 關鍵字是非常好的方式。在結束後, 它會幫你正確的關閉檔。 而且寫起來也比 try - finally 語句塊要簡短:
... read_data = f.read()
>>> f.closed
True
檔對象還有其他方法, 如 isatty() 和 trucate(), 但這些通常比較少用。
pickle 模組
python的pickle模組實現了基本的數據序列和反序列化。
通過pickle模組的序列化操作我們能夠將程式中運行的對象資訊保存到檔中去,永久存儲。
通過pickle模組的反序列化操作,我們能夠從檔中創建上一次程式保存的對象。
基本介面:
pickle.dump(obj, file, [,protocol])
有了 pickle 這個對象, 就能對 file 以讀取的形式打開:
x = pickle.load(file)
注解:從 file 中讀取一個字串,並將它重構為原來的python對象。
file: 類檔對象,有read()和readline()介面。
實例 1
import pickle
# 使用pickle模組將數據對象保存到檔
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
實例 2
import pprint, pickle
#使用pickle模組從檔中重構python對象
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()