有两种形式的数据的分析,可以用于描述一种重要的类提取物的模型或预测未来的数据趋势。这两种形式如下:
-
分类
-
预测
这些数据的分析,有助于我们更好地理解大数据。分类预测分类和预测模型预测连续值函数。例如,我们可以建立一个分类模型,以银行贷款申请归类为安全或危险的,或者预测模型来预测在计算机设备给他们的收入和职业美元的潜在客户的支出。
什么是分类?
以下情况下数据分析任务是分类的例子:
-
银行信贷员要对数据进行分析,以便知道哪些客户(借款申请人)是有风险的,或哪些是安全的。
-
营销经理在一家公司需要分析猜测与给定轮廓的顾客会购买一台新电脑。
在上述两个例子,一个模型或分类器被构造来预测类别的标签。这些标签都是有风险的或安全的贷款申请资料和yes或no的营销数据。
什么是预测?
以下情况下的数据分析任务是预测的例子:
假设营销经理需要预测多少给定的客户将在出售他的公司花。在这个例子中,我们刻意去预测数值。因此,数据分析的任务就是例子数值预测的。在这种情况下,模型或预测将构造,预测的连续值的函数或指令值。
注:回归分析是最常用的数字预测的统计方法。
如何分类运作?
我会尽量让你明白如何分类的?与我们上面所讨论的银行申请贷款的帮助。数据分类过程包括两个步骤:
-
构建分类器或模型
-
利用分类器进行分类
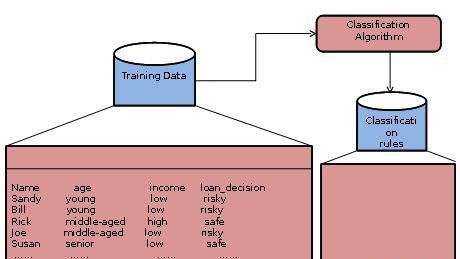
建设中的分类器或模型
-
这个步骤是在学习步骤或学习阶段。
-
在此步骤中,分类算法构建分类器。
-
分类器是从训练集由数据库元组和其相关联的类别标签的构建。
-
构成所述训练集合中的每个元组被称为一个类或类。这些元组也可以被称为样品,对象或数据点。
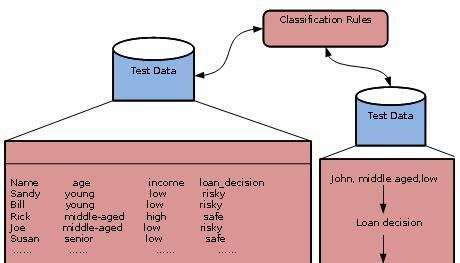
利用分类器进行分类
在此步骤中,分类器被用于分类。这里的测试数据来估算的分类规则的准确性。分类规则可以应用到新的数据元组,如果准确度被认为是可以接受的。
分类和预测问题
主要的问题是准备数据的分类和预测。准备数据包括以下活动:
-
数据清理 - 数据清理涉及删除缺失值的噪声和治疗。噪声是通过运用平滑技术和遗漏值的问题是由最常出现的值该属性替换缺失值解决了删除。
-
相关分析 - 数据库也可具有不相关的属性。相关分析是用于了解任意两个给定的属性是否相关。
-
数据转换和减少 - 该数据可通过任何以下方法进行变换。
-
正常化- 该数据是使用归一化变换。归一化处理包括缩放为给定属性的所有值,以使它们落入一个小的指定范围内。归一化时使用的学习步骤中,涉及计量的神经网络或方法的使用。
-
概括 - 该数据也可以通过将其推广到更高的概念转化。为此,我们可以使用概念层次。
-
注意:数据也可以通过一些其他方法,如小波变换,离散化,直方图分析,聚类和减少。
分类和预测方法的比较
这里是标准的分类比较和预测的方法:
-
准确性 - 分类的准确性是指分类的正确预测的类标签的能力和预测的准确性是指在给定的预测在多大程度上能够猜出预测属性的值的一个新的数据。
-
速度 - 这指的是计算成本中生成和使用的分类器或预测。
-
稳健性- 它指的是分类或预测的,从给定的噪声数据做出正确的预测能力。
-
可扩展性- 可扩展性是指构建分类或预测有效地给予大量数据的能力。
-
解释性- 这指的是在何种程度上的分类或预测理解。