文本数据库包括最庞大的收集文件。他们从几个来源,如新闻文章,书籍,数字图书馆,电子邮件和网页等。由于增加的信息量收集这些信息,文本数据库正在迅速增长。在许多文本数据库的数据结构半。
例如,一个文档可能包含一些结构化的字段,如标题,作者,publishing_date等,但随着结构数据的文档也包含非结构化的文本成分,如摘要和内容。不知道什么可能是在文档中,因此很难制定有效的查询,用于从数据分析和提取有用的信息。要比较的文件和排名的文档的用户需要的工具的重要性和相关性。因此,文本挖掘已经成为流行和重要的主题,在数据挖掘。
信息检索
信息检索处理的信息从大量的基于文本的文档检索。一些数据库系统通常不存在于信息检索系统中,因为两个处理不同类型的数据。以下是信息检索系统中的示例:
-
在线图书目录系统
-
在线文件管理系统
-
站内搜索系统等。
注: 在信息检索系统的主要问题是要根据用户的查询在一个文档集合查找相关文档。这种用户的查询是由一些关键字的描述信息需要。
在这种类型的搜索问题的用户采取主动从集合拉的相关信息了。这是适当的时候用户有临时需要的信息即短期需要。但如果用户有长期需要的信息,然后在检索系统也可以主动采取任何新到达的信息项推给用户。
这种获取信息的被称为信息过滤。和相应的系统被称为过滤系统或推荐系统。
用于文本检索的基本措施
我们需要检查系统如何准确或正确的是当系统检索了一些文件的用户的输入的基础上。让该组与查询相关的文档被表示为{Relevant}和集合中检索文档的定义为{}检索。该组是相关和检索的文档可以被表示为 {Relevant} ∩ {Retrieved}这可以被显示在维恩图中,如下所示:
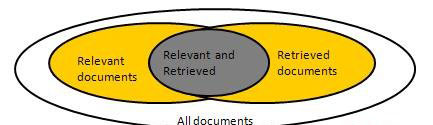
有评估文本检索的质量三项基本措施:
-
Precision
-
Recall
-
F-score
精密
精度是检索到的文档的相关的查询是实际上的百分比。精度可以被定义为:
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
召回
召回的文档是相关的查询,并在事实上检索到的百分比。召回的定义为:
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F-SCORE
F值是常用的权衡。信息检索系统往往需要权衡精度或反之亦然。 F值被定义为召回或精密的调和平均数如下:
F-score = recall x precision / (recall + precision) / 2